A few days ago, I was working on a side project and wanted to hide a few files from Git. In the process, .gitignore caught my eye, and I started digging deeper into it. .gitignore ignores files or directories but doesn’t hide them, but how? Let’s investigate!
A .gitignore file is used to specify files or directories that should be ignored
by Git when tracking changes in our project.
The purpose of .gitignore is to prevent files from being accidentally committed to repositories that are not intended to.
When we create a project, generally we won’t see a .gitignore file; we have
to manually create it. As a rule of thumb, it has to be located in the root
directory of our Git repository.
Patterns Are Everywhere
If we want to just ignore a file or a directory, we can just open the .gitignore
file and add the name of the file (For example: test.txt) or directory(For
example: /logs) and save it. But what if we want to specify a bunch of files or
directories?
.gitignore has some common patterns such as filename patterns, directory
patterns, negation patterns etc., which help us to ignore bunch of files
altogether.
For instance, in filename patterns, if we specify *.log, it’s going to ignore all .log
files. In case of directory patterns, if we specify /build/, it’s going to
ignore entire build directory.
We can also use negation patterns, like if we use !secret.md, it’s going to
exclude a specific file from being ignored.
Patterns Have Rules
For those of us who are familiar with regex and glob patterns in shell, these rules are pretty easy to comprehend.
* - matches zero or more characters.
? - matches a single character.
# - comments.
/ - directory seperator.
No Hiding
A .gitignore file doesn’t hide files or folders; rather, it instructs Git to
ignore and exclude specific files or directories from being tracked and included
in the version control system. And this is an important aspect. When files are
included in .gitignore, Git will simply disregard them when performing various
operations like git status, git add and git commit.
When we initialize a Git repository or add existing files to it, Git starts
tracking changes in those files. The .gitignore file contains patterns and rules that specify which files or directories should be ignored by Git.
When Git encounters a file or directory listed in the .gitignore file, it checks whether it matches any of the patterns in the file. If there is a match, Git treats that file or directory as “untracked” and does not include it in Git’s operations.
When we run Git commands like git status, git add, or git commit, Git examines the .gitignore file to determine which files should be excluded from these operations.
Files that match the patterns in the .gitignore file are not displayed in git status, and they are not included when we use git add to stage changes.
Finally, when we use git commit, ignored files are not included in the commit, ensuring they are not added to the version history.
Uff, that was a lot. Let’s move on!
Where Do The Files Live
When a file is ignored by a .gitignore rule, it continues to exist in our project’s directory structure on our local file system, but Git does not actively track or manage it.
Meaning, the file is still physically present in the same location as before, but Git treats it as if it doesn’t exist within the context of version control.
Hands On
Time to get our hands dirty and see how .gitignore works.
First, let’s create a dummy repository called test on Github and clone it to our
local machine.
Next we’ll create some files namely, file1, file2, file3, file4 and file5.
Let’s add some content to file1 and include that in .gitignore.
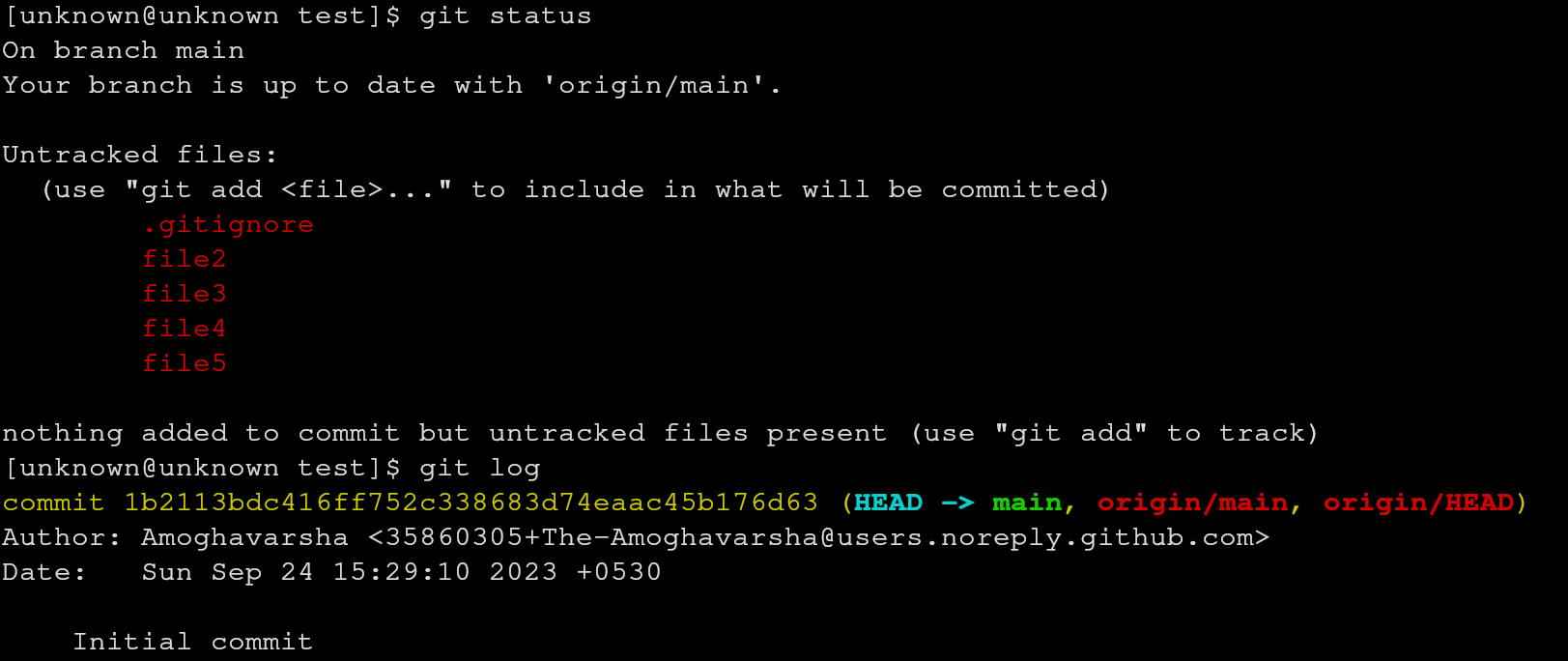 Now as we can see, we can’t see the
Now as we can see, we can’t see the file1 when we use git status as it’s
included in .gitignore.
After we commit and push the changes, let’s check what has happened to our missing file. In order to do that, we can simply type git log --stat to see what has happened to our previous commit.
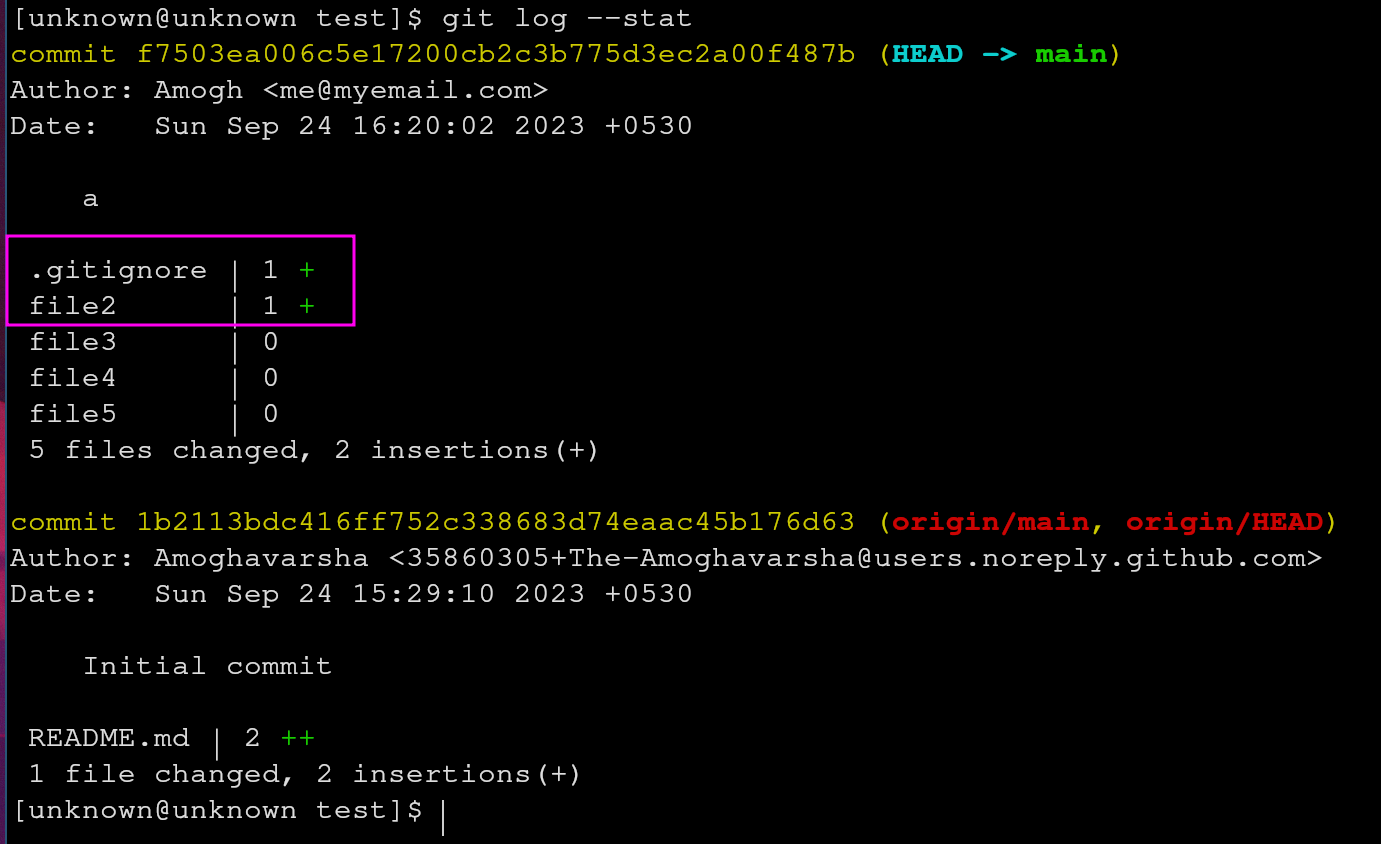 So we can see a change has been made to our
So we can see a change has been made to our file2 and .gitignore.
To investigate further, let’s use git log -p, where p flag
indicates patch.
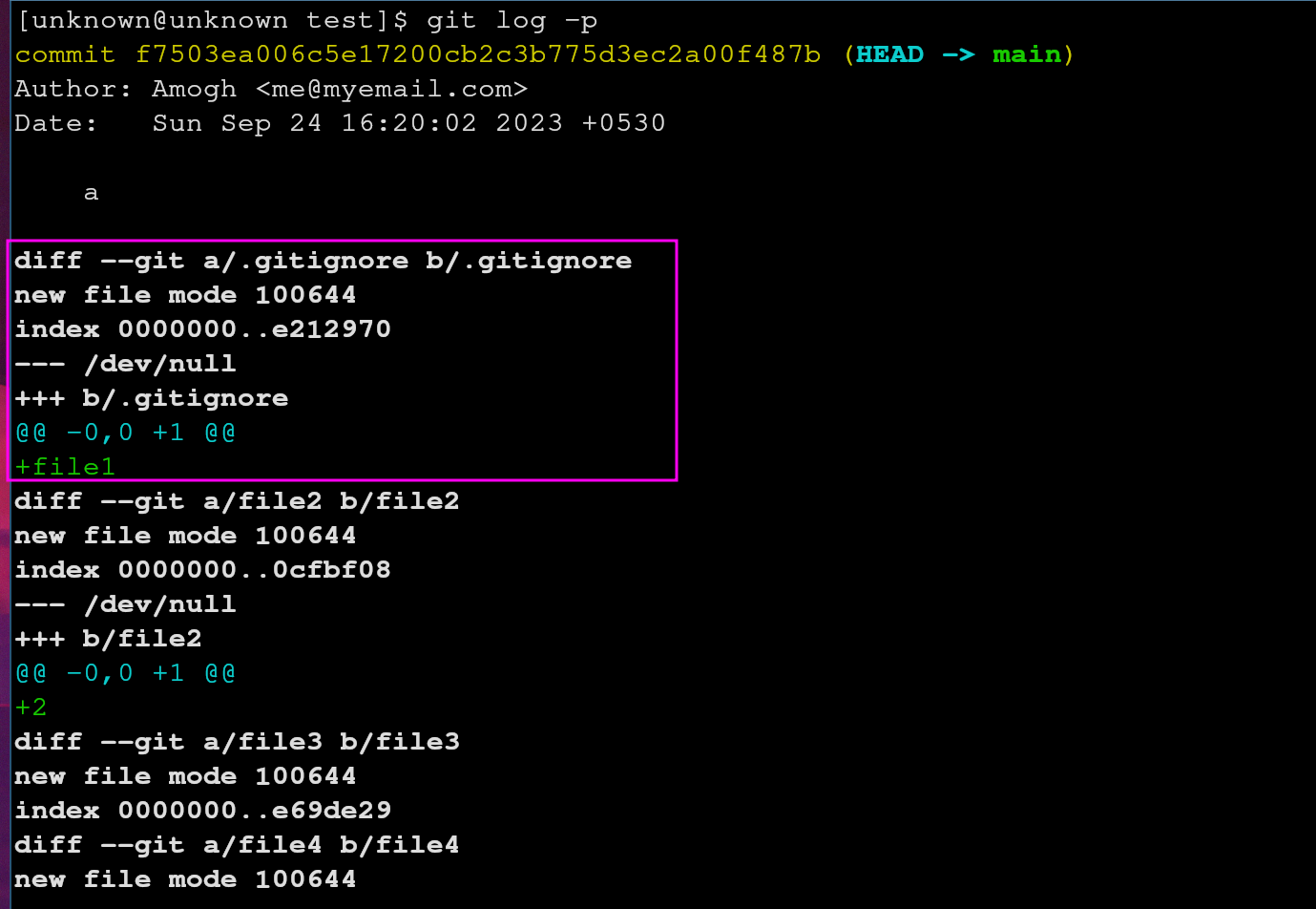 Look what we got here. Let’s break down line by line.
Look what we got here. Let’s break down line by line.
diff --Git a/.gitignore b/.gitignore - This line indicates that Git is showing a difference(diff) between two versions of the same file named .gitignore. The a/.gitignore and b/.gitignore represent the “old” and “new” versions of the file, respectively.
new file mode 100644 - This line specifies the file mode for the new .gitignore file. In this case, it’s set to 100644, which is the standard file mode for regular files in Git.
index 0000000..e212970 - This line shows the Git object IDs (SHA-1 hashes) for the old and new versions of the file. In this case, the old version is represented as all zeros (0000000), indicating that it’s a new file, and the new version has the SHA-1 hash e212970.
/dev/null +++ b/.gitignore - This line is interesting and it indicates that the old version of the file (before the commit) is considered non-existent (/dev/null), and the new version of the file is named .gitignore (the +++ b/.gitignore part).
@@ -0,0 +1 @@ - This line is part of the unified diff format and provides context for the changes. It specifies the line numbers that are being compared between the old and new versions of the file. In this case, it says that there are no lines in the old version (-0,0) and one line in the new version (+1).
Finally, we caught our file1. +file1 - This line represents the actual change made in the commit. It indicates that the new .gitignore file contains one line, which is file1. This means that the commit added a rule to the .gitignore file to ignore a file named file1.
And an important thing to note here is, it’s not going to hide our files. If our repository is public and if someone clones the repository, they can still get information about our commit messages, branch names, file paths and so on.
Then how can we hide our files or make it inaccessible to others? You should wait for my next blog post!
Follow me on other social media